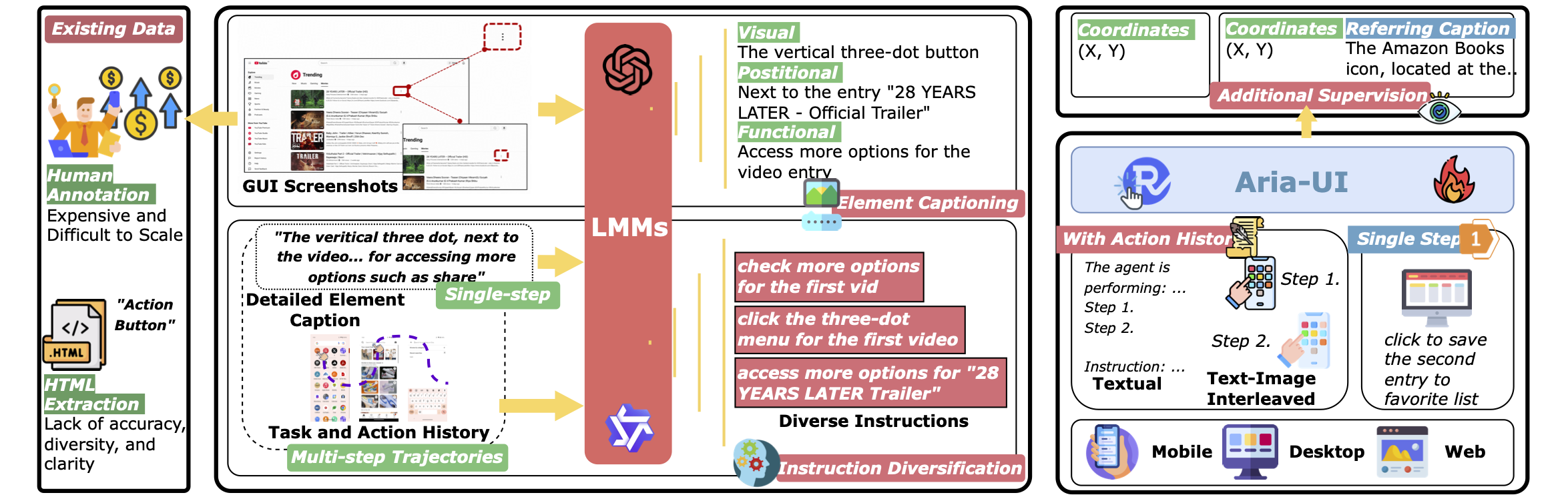
Key Features of Aria-UI
-
✨ Versatile Grounding Instruction Understanding:
Aria-UI handles diverse grounding instructions, excelling in interpreting varied formats, ensuring robust adaptability across dynamic scenarios or paired with diverse planning agents.
-
📝 Context-aware Grounding:
Aria-UI effectively leverages historical input, whether in pure text or text-image-interleaved formats, to improve grounding accuracy.
-
⚡ Lightweight and Fast:
Aria-UI is a mixture-of-expert model with 3.9B activated parameters per token. It efficiently encodes GUI input of variable sizes and aspect ratios, with ultra resolution support.
-
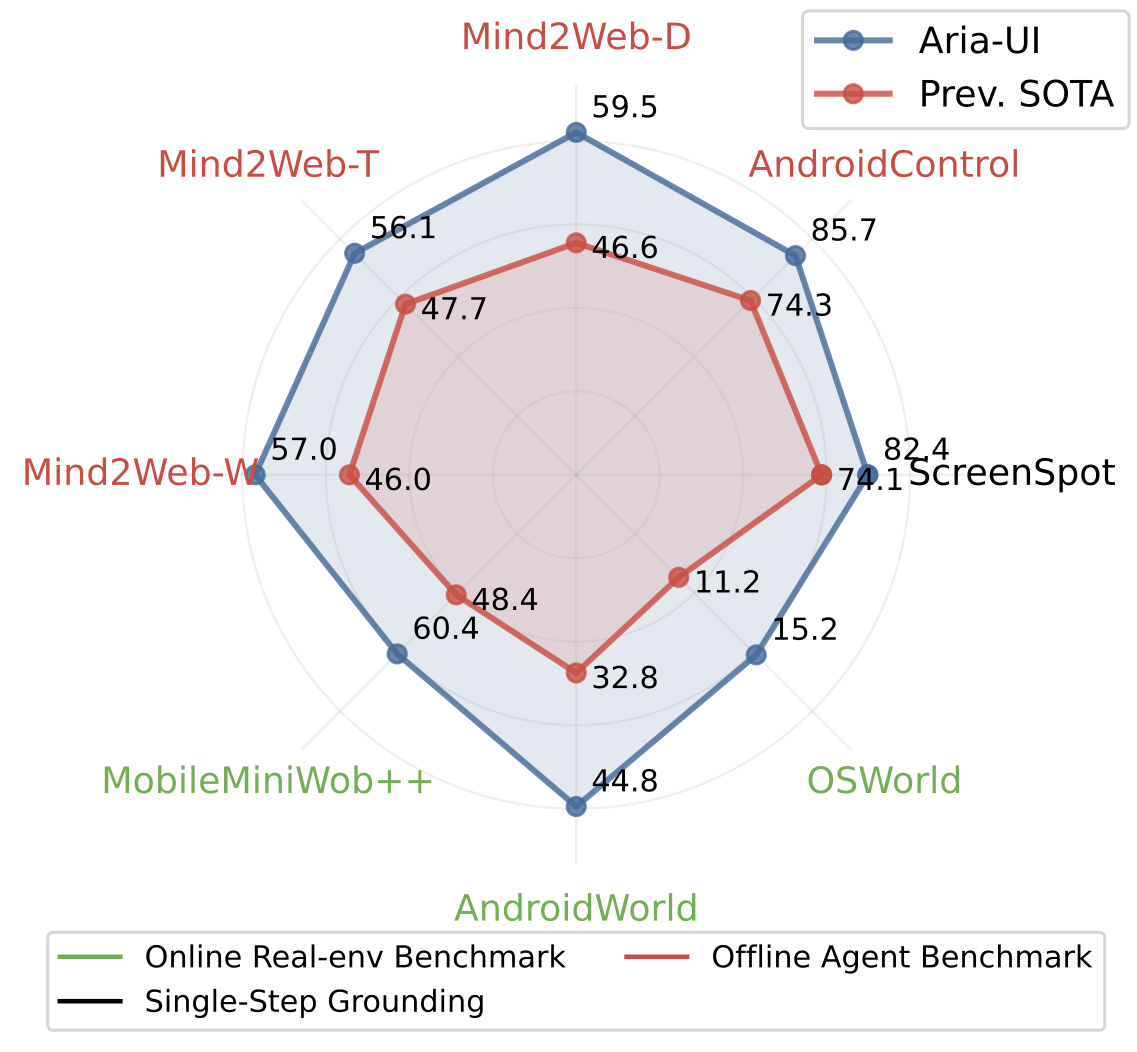
🎉 Superior Performances:
Aria-UI sets new state-of-the-art results on offline and online agent benchmarks. Especially, Aria-UI achieves the 🏆 1st place on AndroidWorld with 44.8% task success rate and the 🥉 3rd place on OSWorld with 15.2% task success rate. (Dec. 2024)